论文阅读纪要
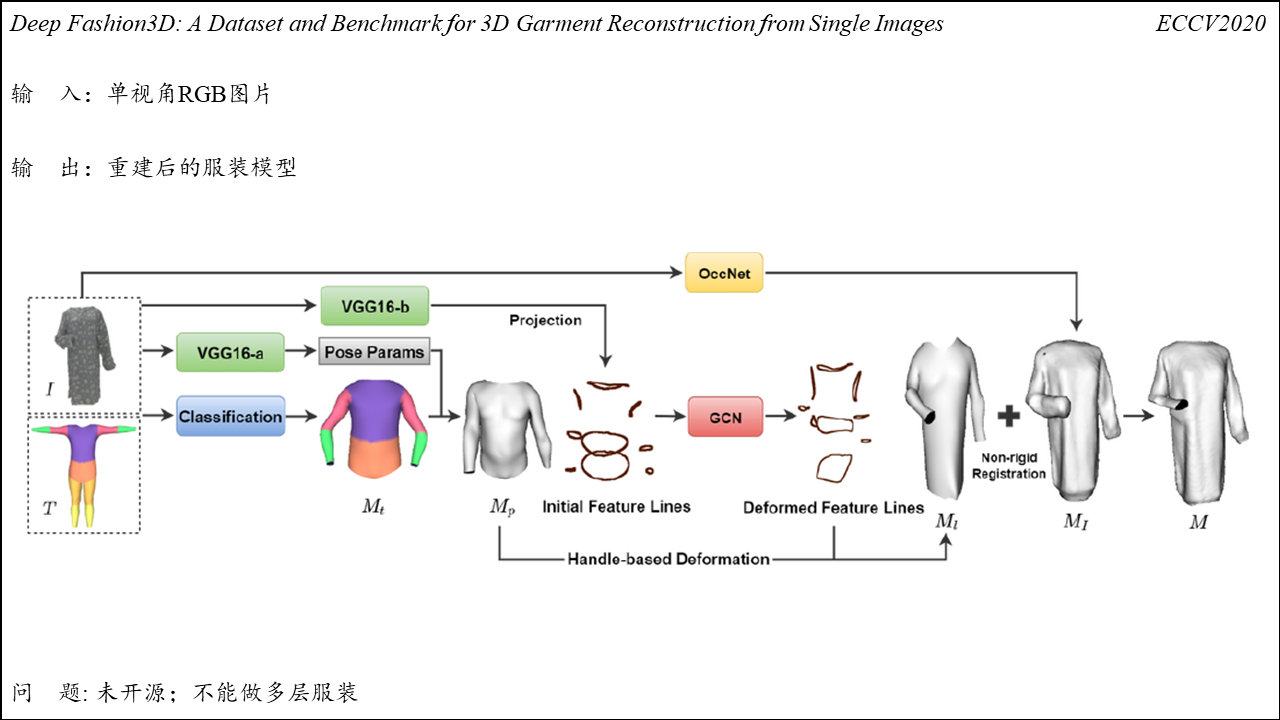
TailorNet
Summary: 将服装变形解耦为高频成分及低频成分,使用拉普拉斯算子对顶点做平滑,得到低频成分,然后使用原顶点坐标减去低频成分得到高频成分。使用MLP对高频特征进行融合,然后与低频成分重组,得到目标体型及姿态下的服装变形。合成出的服装具有丰富的褶皱细节,且方法相较于PBS快1000倍。
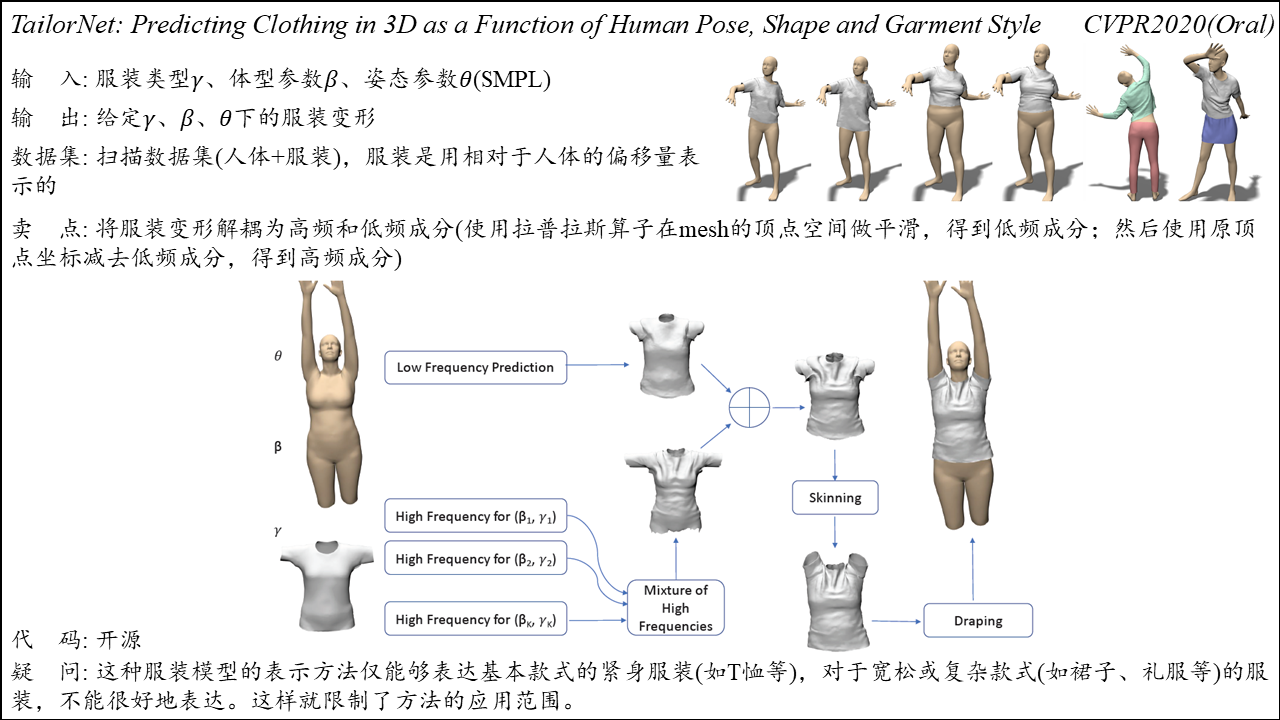
Mesh-Based Autoencoders for Localized Deformation Component Analysis
Summary: 在变形梯度之上引入的卷积的概念,使得网络能够获得更好的特征表示,卷积核的定义为当前点与其一阶领域的加权平均;此外,在Loss中引入稀疏惩罚项,使得网络能够捕获到局部变形。方法可以应用于降维、变形成分分析、重构、形状合成等任务中。
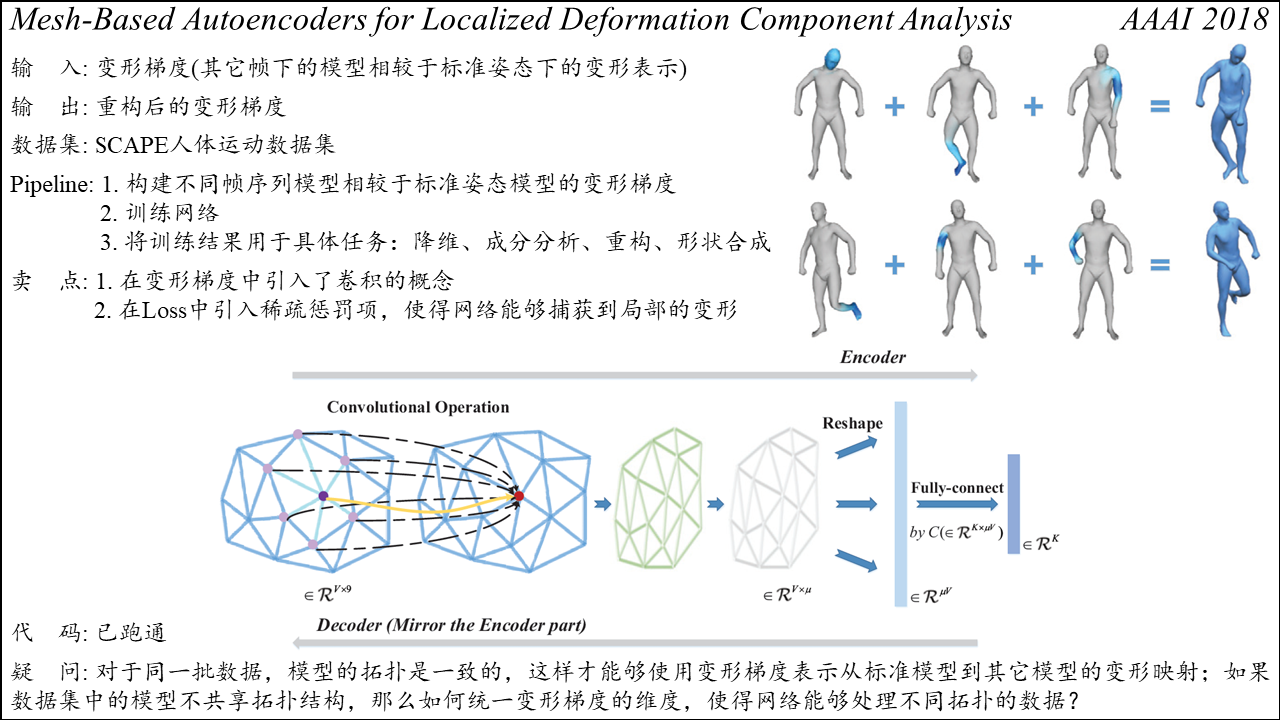
Automatic Unpaired Shape Deformation Transfer
Summary: 给定一组源体型下不同姿态的人体,可生成与源体型姿态一致的目标人体。方法的核心在于提出了VAE-Cycle-GAN,从而允许在不同拓扑的人体间进行deformation transfer。此外,提出了源网格与目标网格视觉相似度的衡量方法。
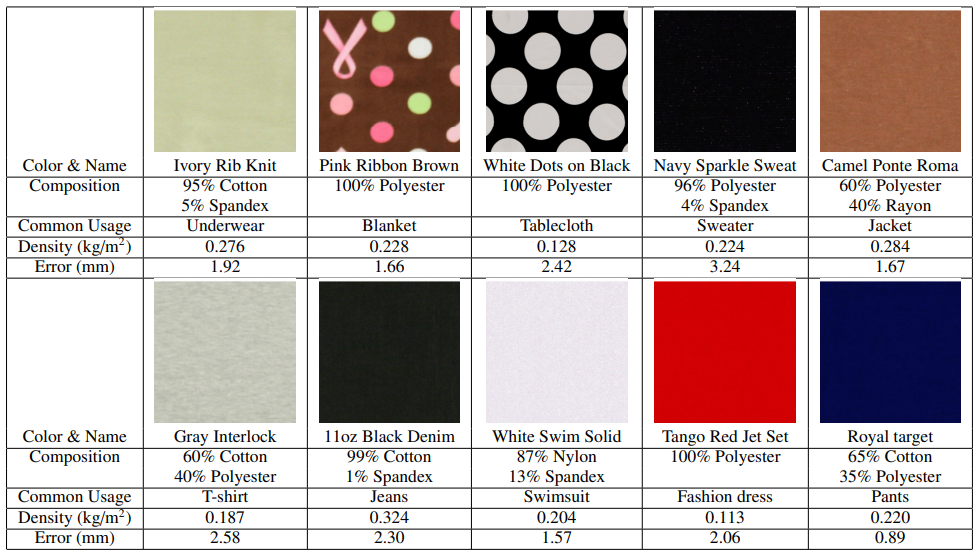
Data-Driven Elastic Models for Cloth: Modeling and Measurement
tog12年的paper,给出了不同材质布料的成分组成,ARCSim仿真时应该用得到。
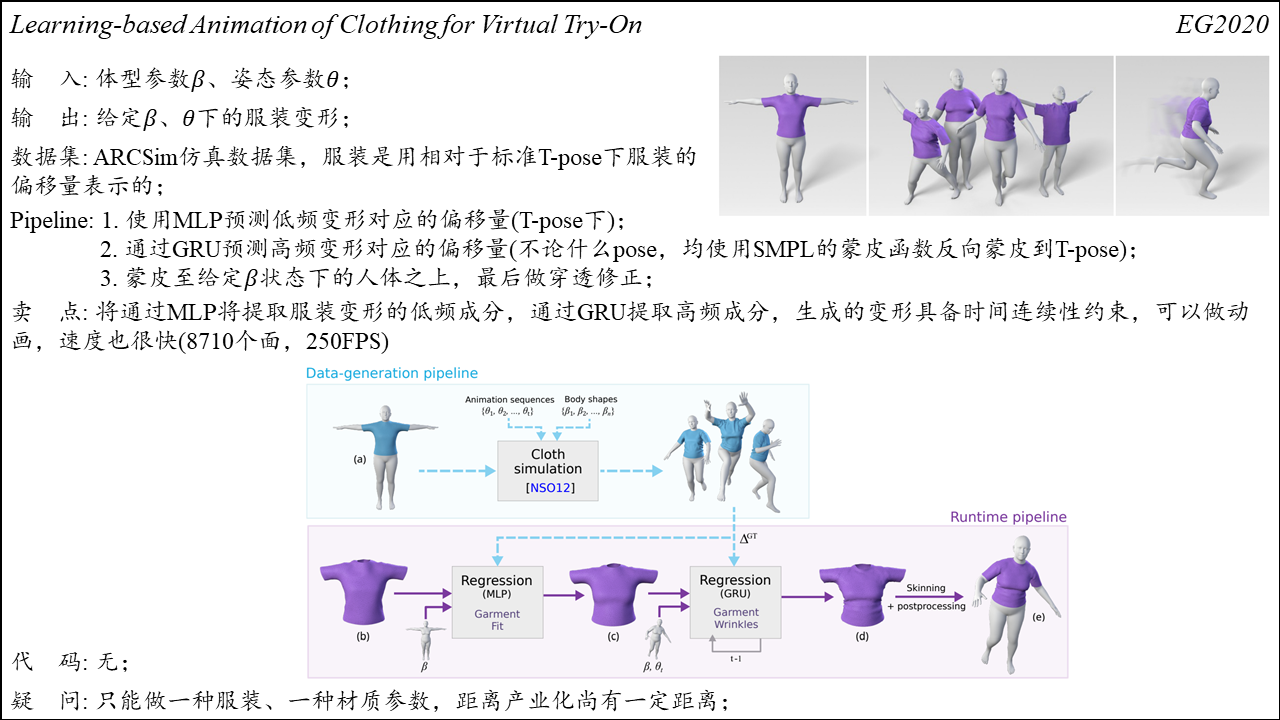
Learning-based Animation of Clothing for Virtual Try-On
Summary:一种基于学习的虚拟试衣方法。将服装看作是相对于人体shape和pose的函数,使用相较于T-pose服装的偏移量去表示服装。方法首先通过MLP学习一个从shape到低频服装变形的映射,然后学习一个从shape+pose到高频服装变形的映射,可以合成出在时间上连续且细节丰富的服装动画。缺点也很明显,目前只能做一种服装、一种材质参数。
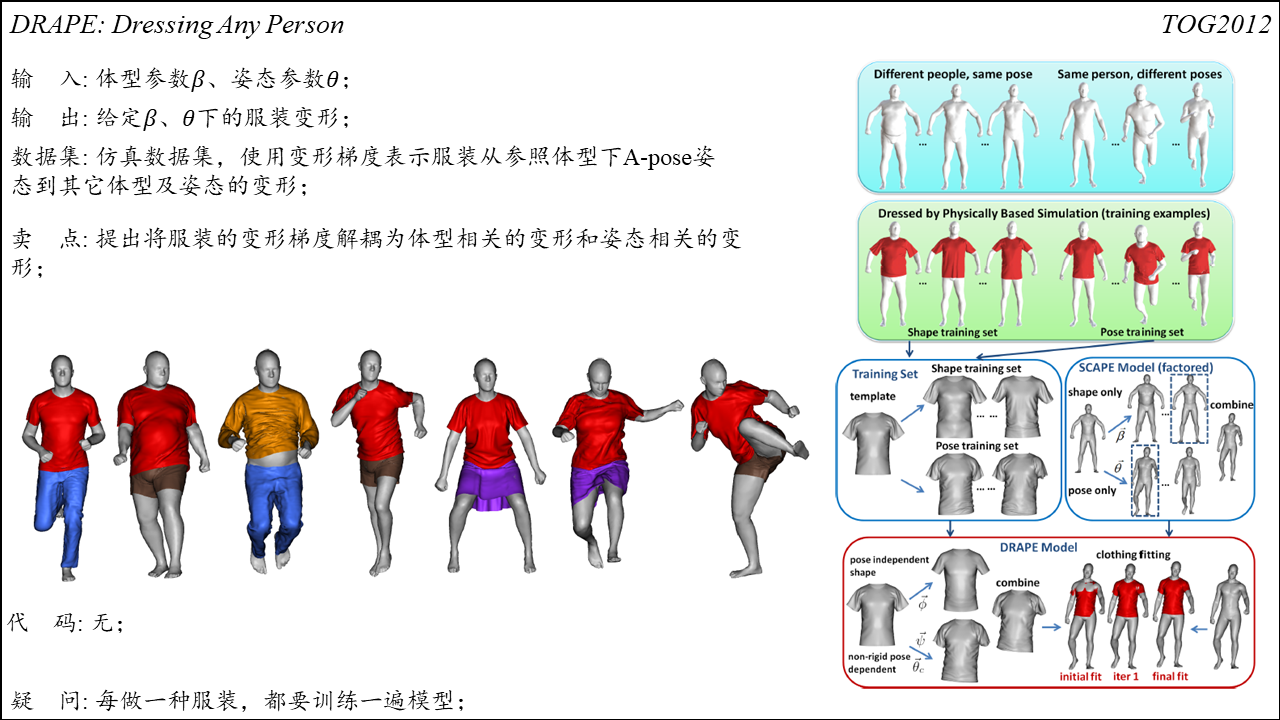
DRAPE: DRessing Any PErson
Summary:相关性学习方法中比较经典的一篇文章,可以将给定款式的服装快速穿着到不同体型和姿态的人体之上。该方法使用变形梯度表示服装变形,然后通过PCA将服装变形解耦为体型相关的变形和姿态相关的变形,然后根据输入的体型和姿态参数对上述两种变形成分进行重组。
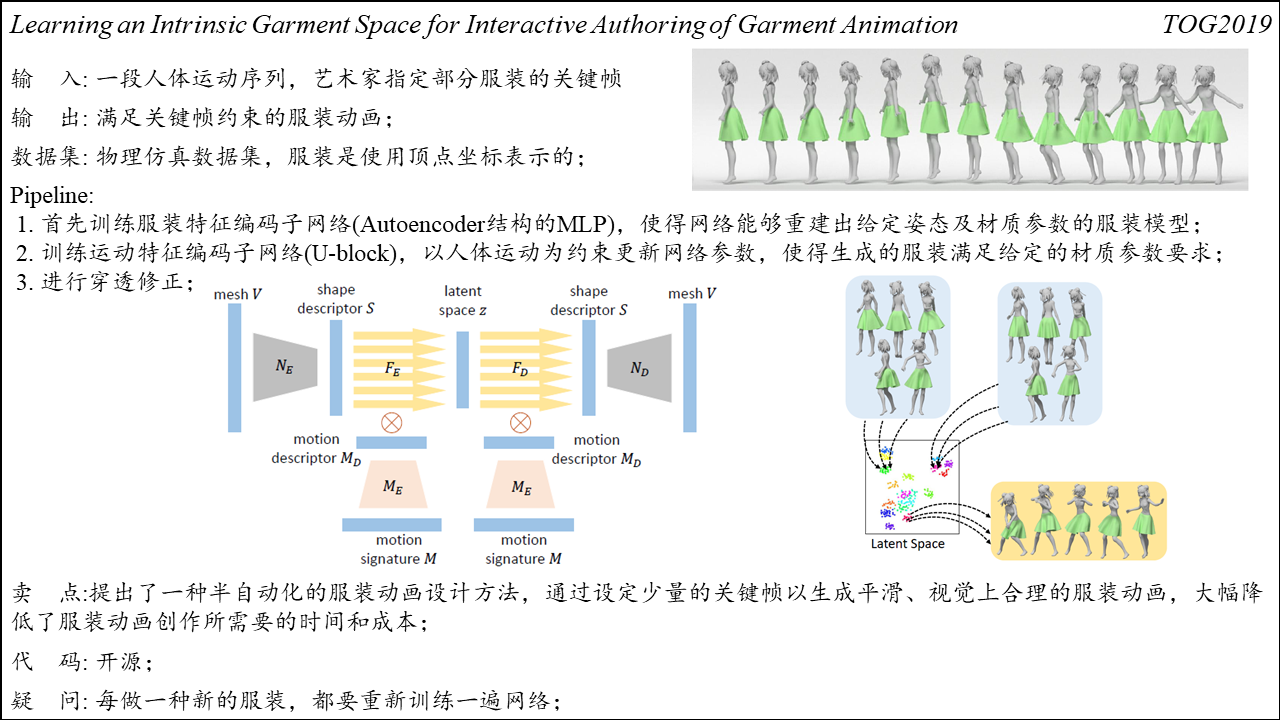
Learning an Intrinsic Garment Space for Interactive Authoring of Garment Animation
Summary:服装动画创作过程中,设计师需要逐帧地指定不同运动人体对应的服装变形,这会带来高昂的时间和经济成本。该工作提出了一种半自动化的服装动画设计方法,设计师只需要指定一段运动序列中少量的关键帧,方法便可以自动补全其它帧的服装运动,从而大幅降低了服装动画创作所需的时间。
DeepWrinkles: Accurate and Realistic Clothing Modeling
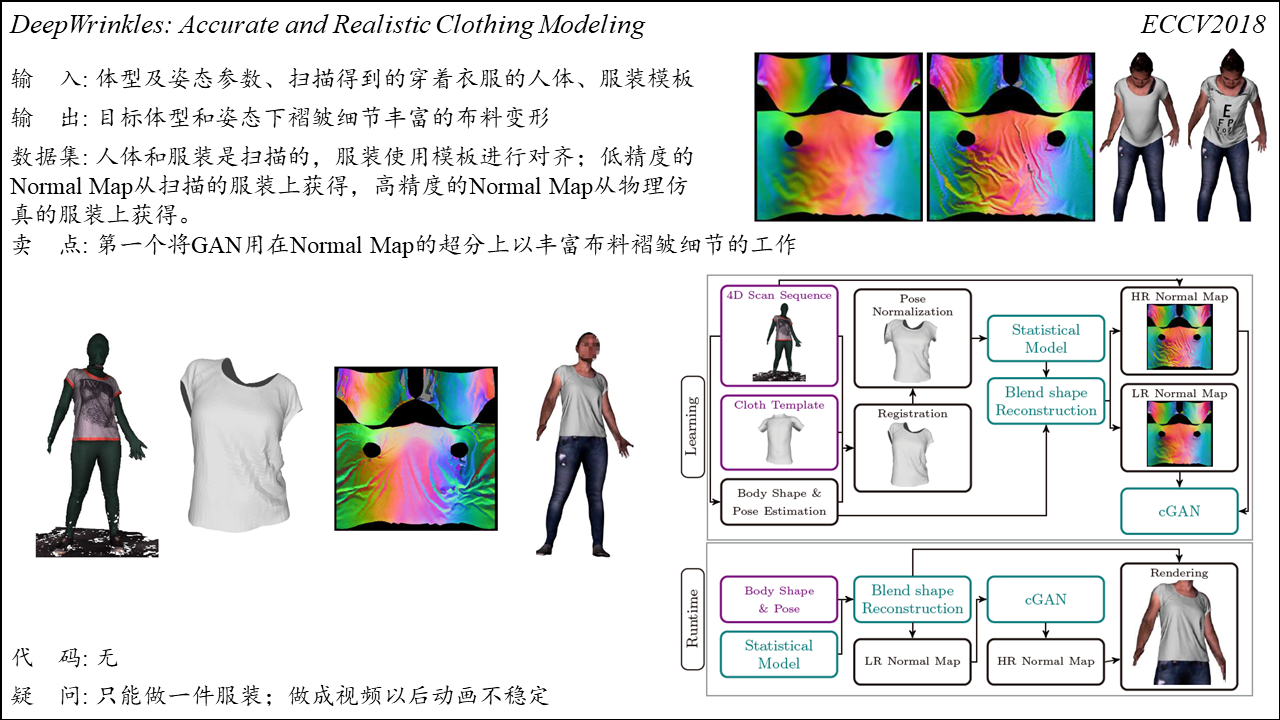
PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization
Summary:可以通过单视角图片重建出完整人体及服装的工作,方法分为几何重建和材质重建两个部分。几何重建阶段,网络首先通过encoder(HourGlass)对每个像素点的特征进行编码,并根据相机参数估算坐标点的深度值,然后以特征向量和深度值为输入使用MLP预测像素点在网格内的概率;材质重建阶段,网络以单张图片及几何重建子网络编码的特征向量为输入,使用MLP预测像素点对应的RGB信息。方法相较于之前的工作效果更好,并且由于方法学习的是关于的像素点是否在网格内的函数,在存储上比较友好。缺点在于对于几何细节的重建效果不够理想,且重建效果依赖于较好的相机参数。
*需要注意的是,方法在三维坐标点的采样策略上做了一些trick,直接在bounding box中均匀采样往往不能得到理想的结果,因为我们关注的是物体表面附近的信息;作者在三维模型的表面附近进行采样,每个顶点在$xyz$三个方向上进行抖动,抖动的距离符合高斯分布$\mathcal N(0, \sigma)$。作者将均匀采样和高斯采样两种方式相结合,可以取得更好的重建效果。
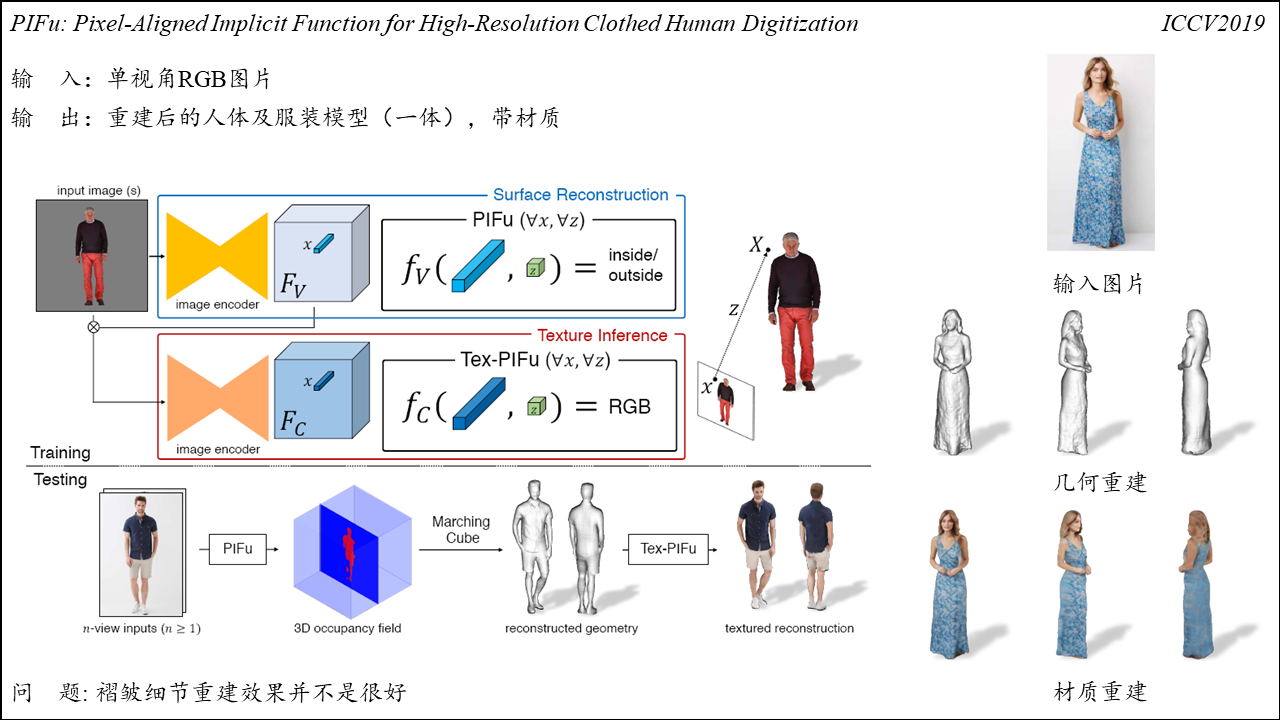
**PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization**
Summart:PIFu的升级版,PIFu使用低分辨率的图像进行几何重建,低分辨率的图像可以带来更大的感受野(空间信息),但是会丢失几何细节。针对上述问题,PIFuHD使用两个网络进行几何重建:一个粗略估计重建对象的全局形状、另一个专注于重建局部的几何细节,然后将上述两个网络捕获到的信息进行融合,以重建出高精度的三维模型。网络的输入是单张RGB图像,大小为$1024 \times 1024$,粗略估计阶段,使用encoder将图像编码为大小为$128 \times 128$的特征,然后在深度信息的输入下通过MLP预测像素点在网格表面的概率;精确预测阶段,输入为单张$1024 \times 1024$的RGB图像以及对应的法线贴图(通过pix2pixHD得到),得到大小为$512 \times 512$的图像特征,然后以该特征和粗略估计阶段得到的全局特征为输入同样通过MLP预测像素点在网格表面的概率。
*需要关注的是,在重建误差的选取方面,作者并未采用常见的$L_{1}$或$L_{2}$误差项,而是选取了Extended BCE(Binary Cross Entropy)优化重建结果,当处于网格内外的坐标点数量不同时,损失函数会给数量较少的一方相对更大的权重。
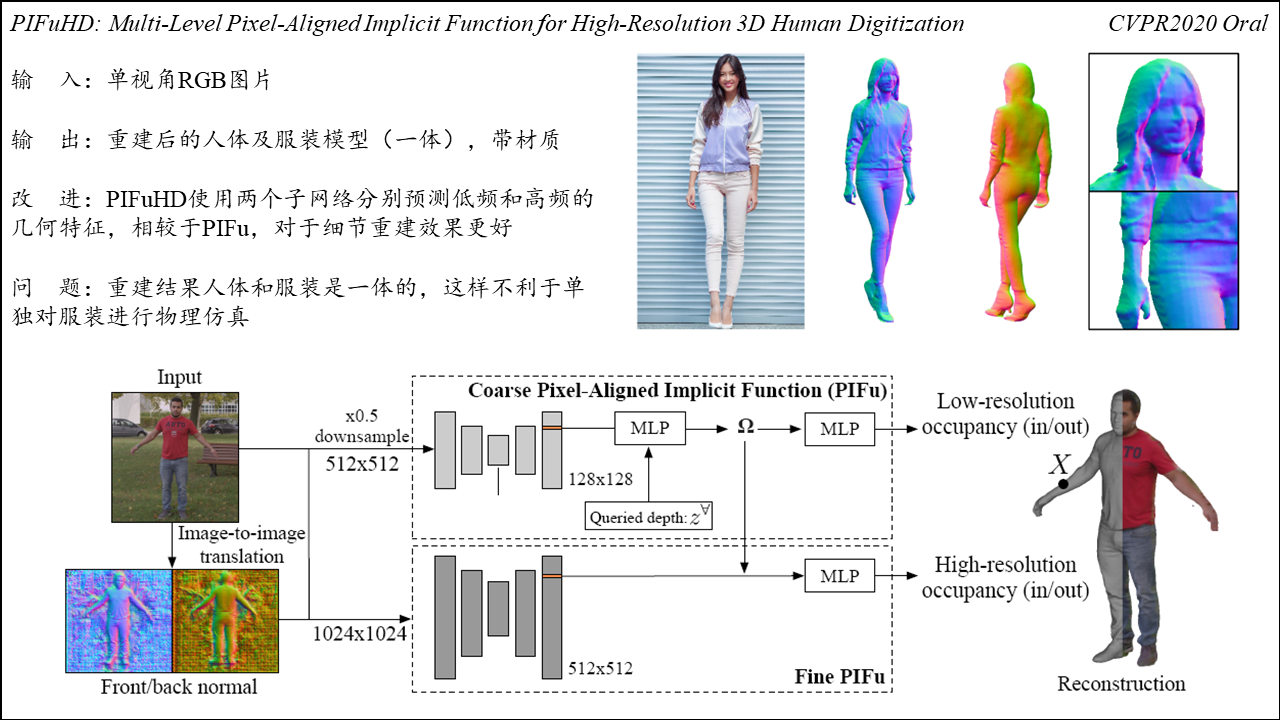
Physics-Inspired Garment Recovery from a Single-View Image
Summary:该工作可以根据单张图片重建出人体及三维服装模型,并根据估算得到的身体参数对服装尺码进行调整。输入为单视角图片,方法首先识别出图片中服装的种类,然后重建出对应姿态下的人体模型,并对人体的参数进行估计;其次,该方法使用识别出的服装种类在数据库中进行匹配,然后将匹配得到的三维服装模型注册至人体之上;然后,方法通过估算出的人体参数对服装样板进行调整以符合人体尺码,并通过物理仿真的方式迭代地更新服装参数,最终得到重建出的人体和服装模型。方法的问题在于服装重建依赖数据库中的模板匹配,如果数据库中没有对应预制的服装类型,则无法进行重建,这也导致方法无法对复杂款式的服装进行重建。
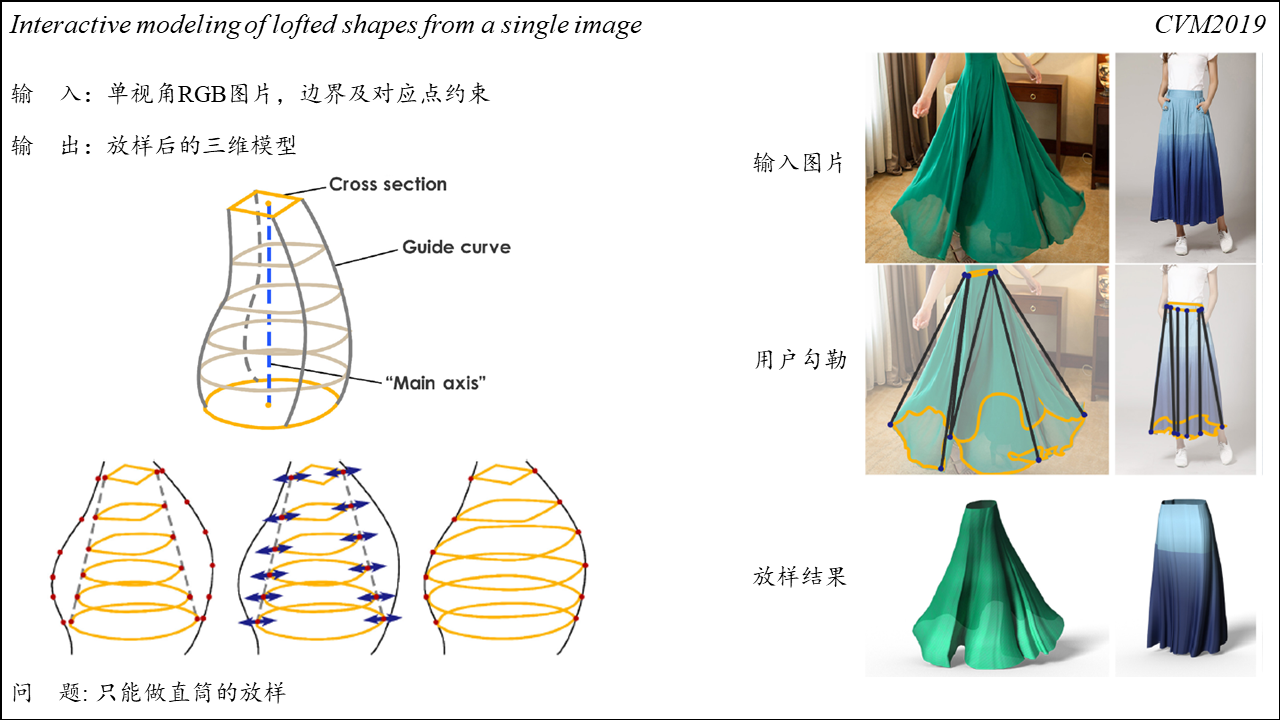
Interactive modeling of lofted shapes from a single image
Summary:这篇比较有意思,可以根据输入的单张图片和用户勾勒的边界约束放样出种类丰富的三维模型。用户需要指定的是放样的边界、放样路径及放样边界上部分关键点的对应关系,然后,方法对用户勾勒的放样边界进行插值以生成若干个中间放样路径。方法的问题在于只能做直筒形状的放养,如果放样路径不是唯一的,就比较麻烦。
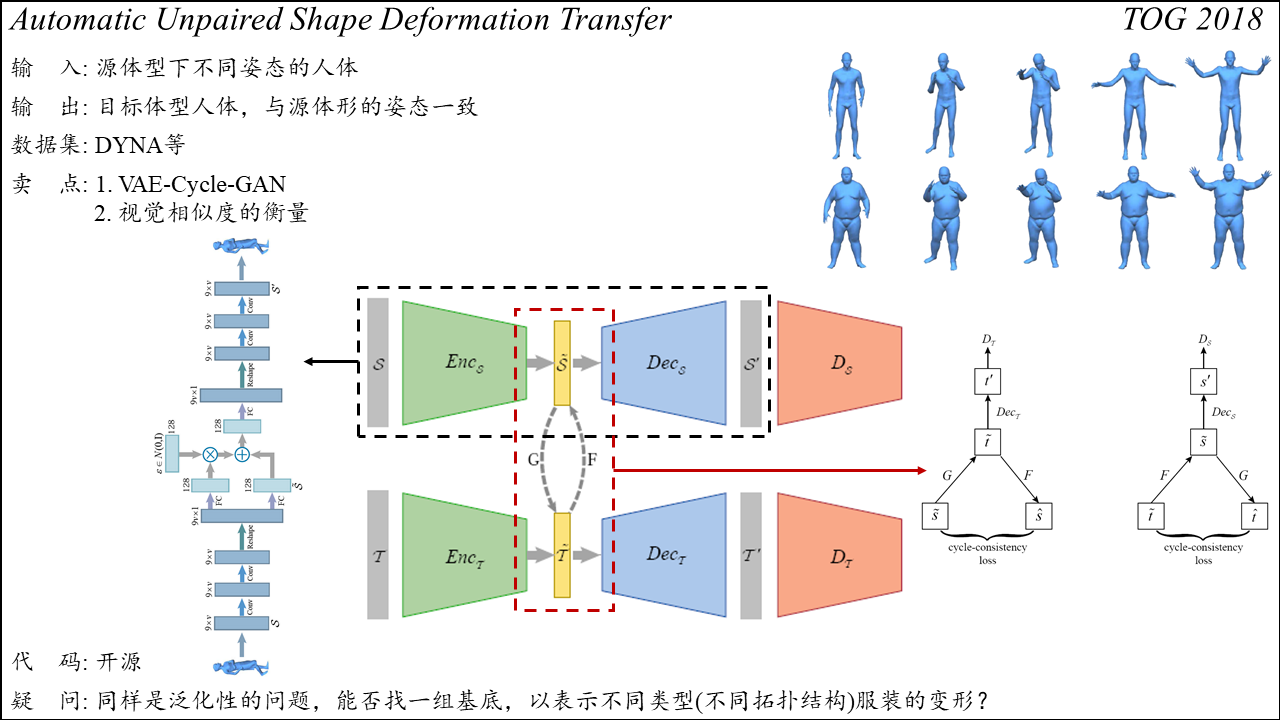
Deep Fashion3D: A Dataset and Benchmark for 3D Garment Reconstruction from Single Images