Learning an Intrinsic Garment Space for Interactive Authoring of Garment Animation
前导内容

这篇文章是Siggraph Asia 2019年的一篇文章,作者是米哈游公司的员工,点这里可跳转到文章主页。
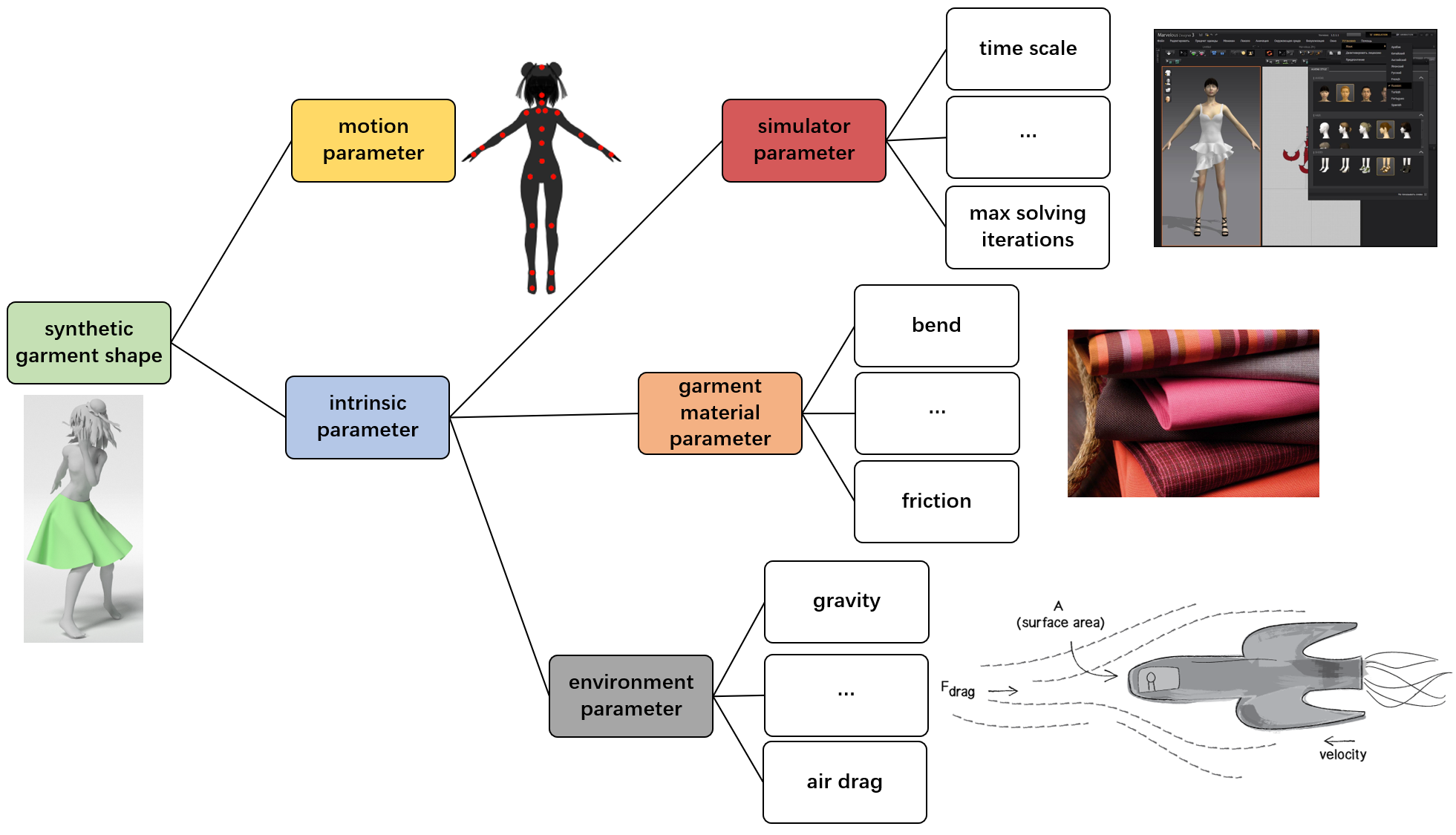
整篇文章是基于一个假设而展开的:服装形变由两个部分组成:人体的姿态参数(黄)以及服装的固有参数(蓝)
人体姿态参数: 即人体的关节运动信息,红色的点代表关节点。
服装的固有参数: 由以下三个部分组成:
-
模拟器参数(红):模拟器通过对服装进行物理仿真,可以将服装穿着到人体之上,其设定会影响服装形变,如仿真时长、最大迭代次数;
-
服装材质参数(橙):不同材质的服装具有不同的材质属性,进而影响到服装的摩擦力、弯曲程度等信息;
-
环境参数(灰)组成:由环境引起的服装形变,如重力、空气阻力等
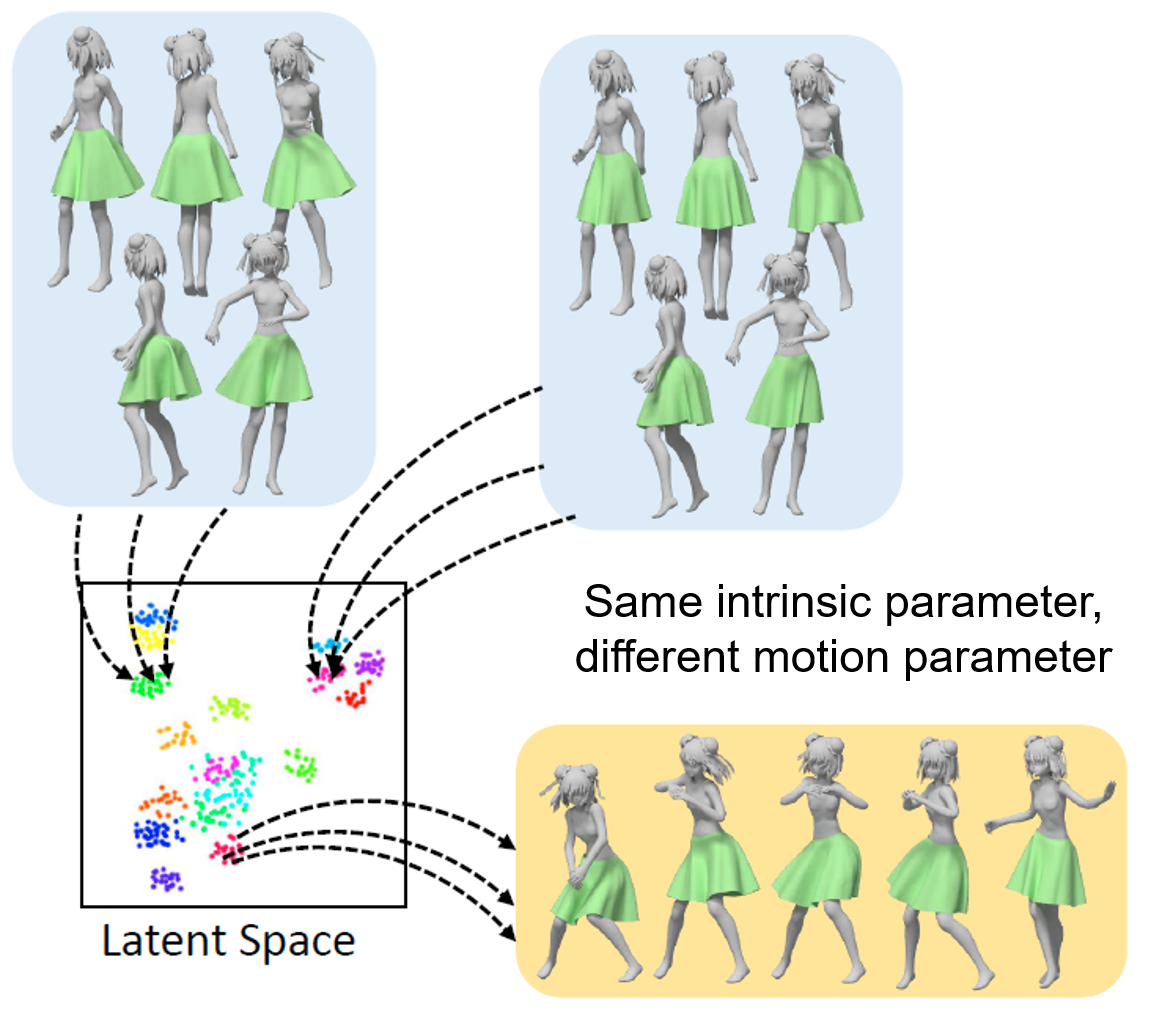
下图给出了三组服装动画序列,同一组的服装具有相同的服装固有参数,而具有不同的人体姿态参数。不同组的服装具有不同的服装固有参数。可以看出,具有相同服装固有参数的服装在隐空间中学到的表达汇集在了同一个区域内,这样便可以区分出具有不同服装固有参数的服装。接下来,再根据给定姿态的人体,利用解码器将隐空间中的降维表示解码为具有不同固有参数的服装造型。
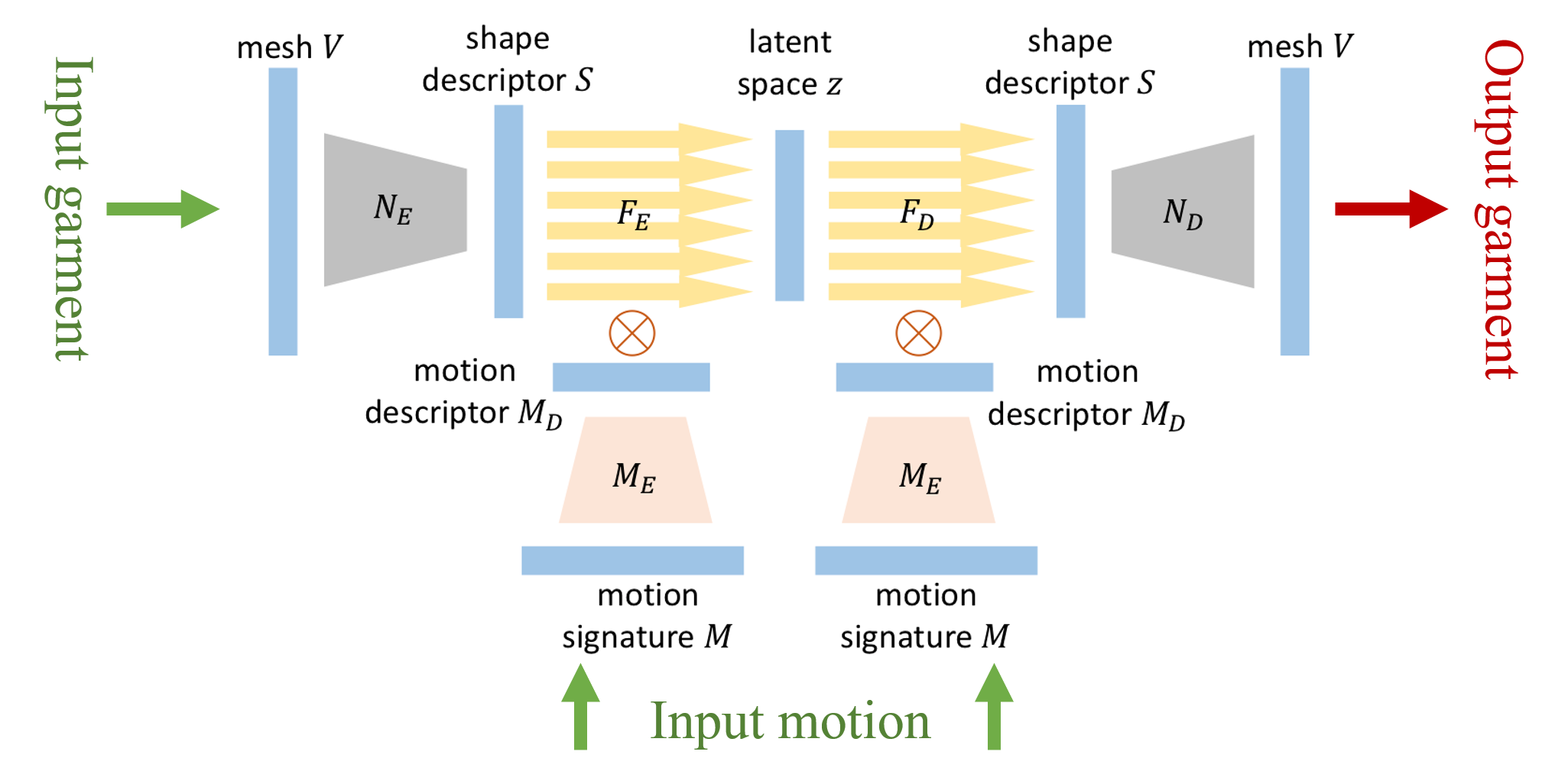
网络结构
接下来介绍文章的网络结构,整体上看,网络由多个自编码器嵌套而成。输入由人体运动序列M和服装模型V两个部分组成(绿),输出为符合目标人体姿态的服装模型(红),如下图:
第一个部分是下图虚线框标出的部分,这一部分负责学习给定服装模型的形状特征:
现在把这个部分先单独拿出来看
- \(V\)代表输入的服装,是一个网格模型(mesh)
- \(S\)代表提取到的形状特征,是\(V\)的降维表达,其维度远小于\(V\)
- \(N_{e}\)代表编码器,负责将输入的\(V\)映射到低维空间\(S\)上
- \(N_{d}\)代表解码器,负责将服装形状特征S的维度还原至与输入的\(V\)一致
这样做的目的有两个:
1.降低输入数据的维度,减少运算量;
2.不同类型服装的顶点数不同,这样做可以统一不同服装对应形状特征的维度;
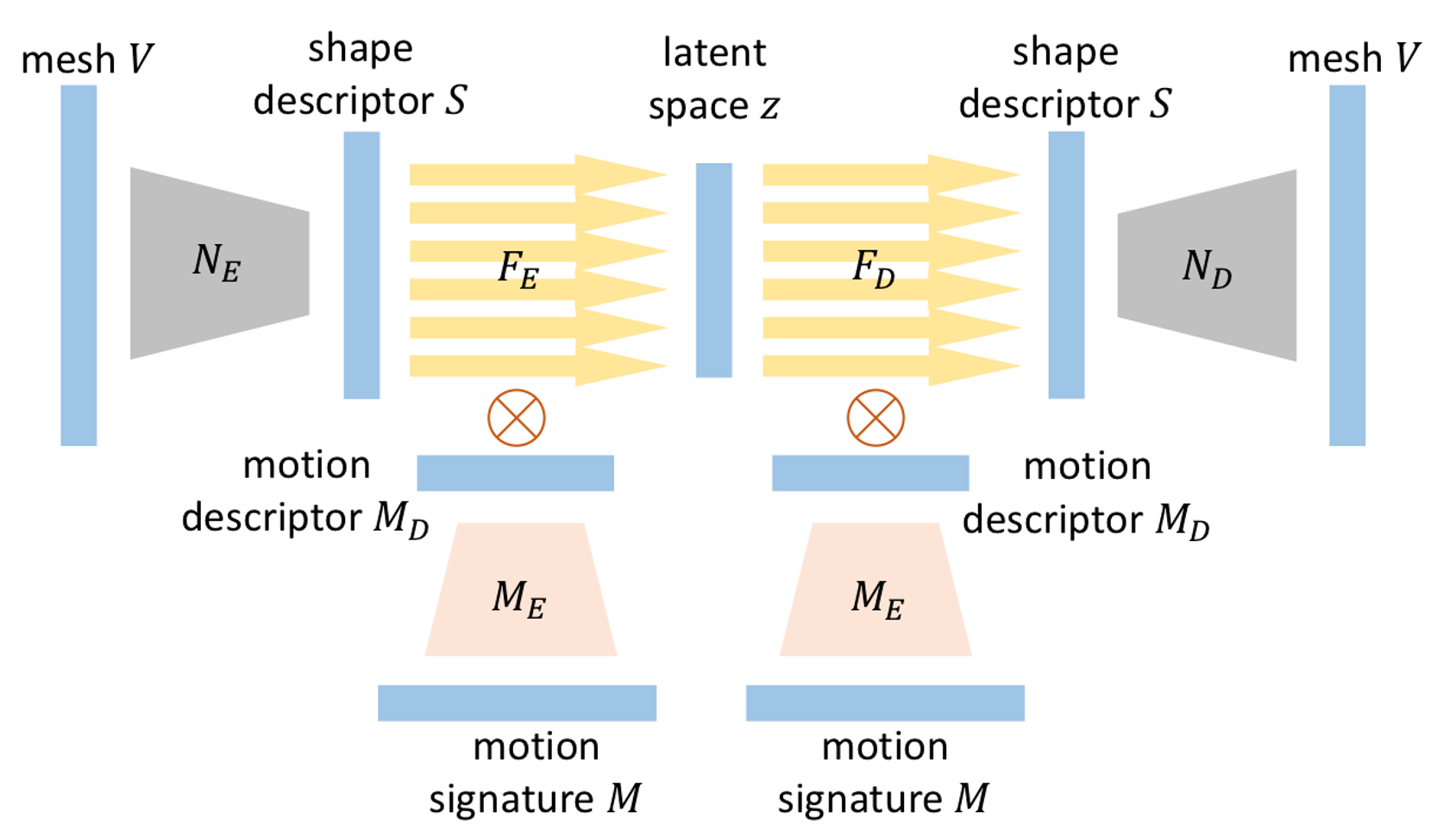
第二个部分是下图虚线框标出的部分,这一部分负责将给定姿态下的人体及其对应的服装模型投影到一个隐空间z中:
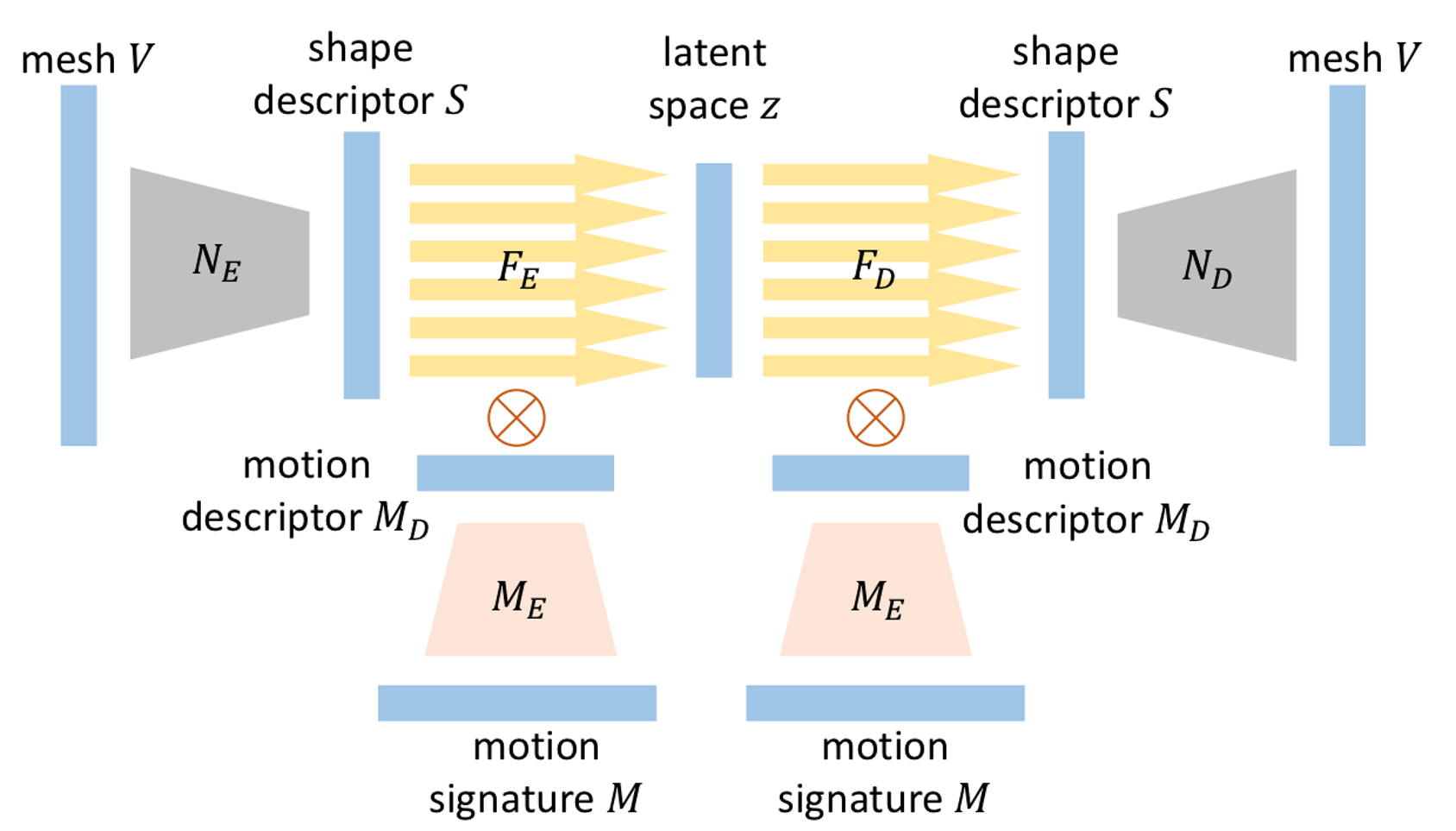
- \(M\)代表人体的动作序列,由当前帧对应的姿态与其前\(W\)帧对应的姿态组成,总共有\((W+1)\)帧;
- \(M_{e}\)是一个编码器,负责将人体动作序列\(M\)进行降维,得到人体姿态特征\(M_{d}\),这一做法与刚刚介绍的服装形状特征的提取类似;
- \(Fe\)代表编码器,负责将服装形状特征\(S\)和人体姿态特征\(M_{d}\)映射到隐空间\(z\)之上;
- \(F_{d}\)代表解码器,负责利用隐空间\(z\)和人体姿态特征\(M_{d}\)还原出与原始维度一致的服装形状特征\(S\)。
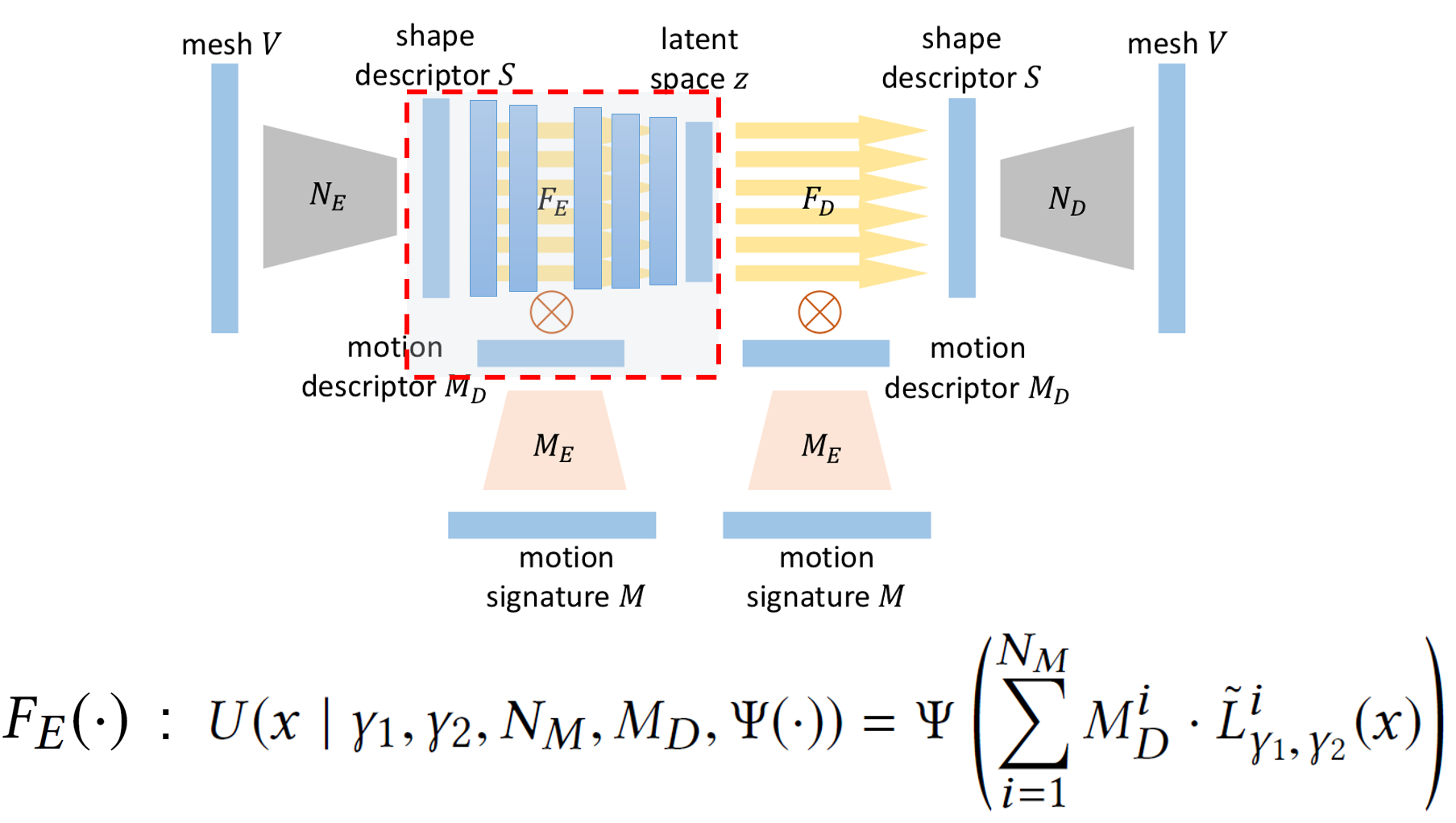
\(F_{e}\)实际上是一个多层的Encoder:
- \(x\)代表当前处理的层
- \(\gamma_{1}\)代表当前处理层的维度,\(\gamma_{2}\)代表下一层的维度
- \(\tilde{L}_{\gamma_{1} ,\gamma_{2}}^i\)表示\(\gamma_{1}\)和\(\gamma_{2}\)所对应的隐藏层间的线性变换
- \(M_{d}\)代表人体姿态特征
- \(N_{m}\)代表\(M_{d}\)的维度
- \(\Psi\)代表不同隐藏层的激活函数
\(F_{d}\)的过程与\(F_{e}\)对称。
总地来说,网络运行的流程可以表示为四个步骤:
Step1: 对于给定姿态下的某件服装,网络首先通过\(N_{e}\)提取出服装形状特征\(S\),并通过\(M_{e}\)提取出人体姿态特征\(M_{d}\);
Step2: \(F_{e}\)在服装形状特征\(S\)和人体姿态特征\(M_{d}\)的共同驱动下学习一个与人体姿态无关的隐空间\(z\),将具有不同固有参数的服装类别投影至隐空间中的不同区域;
Step3: \(F_{d}\)以隐空间\(z\)和人体姿态特征\(M_{d}\)为输入,重构出服装形状特征\(S\);
Step4: 最后,\(N_{d}\)利用重构出的\(S\)还原出服装模型\(V\)
损失函数
实际训练过程中,首先训练出服装形状特征\(S\),然后训练网络的剩余部分,这两个子网络的损失函数也是分开计算的。
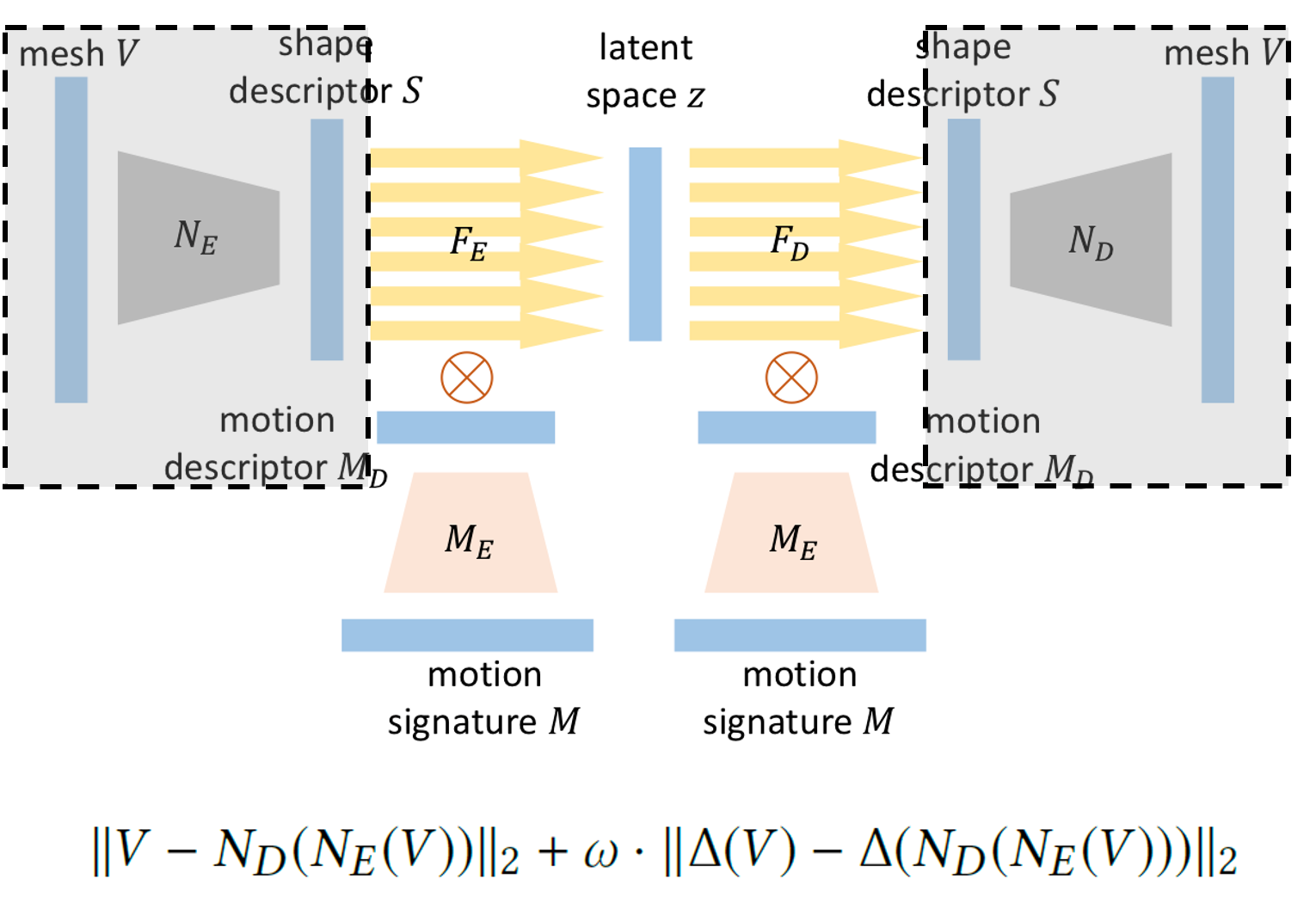
对于服装特征编码子网络,Loss由两个均方误差项组成:
-
顶点坐标均方误差项:对服装模型的顶点进行了约束,V是输入的服装模型的顶点,Ne是Encoder,Nd为Decoder,Nd(Ne(V))代表重构出的服装模型,这一项可以确保重构出的服装模型各顶点的位置与输入的服装模型一致。
-
拉普拉斯均方误差项:对服装模型的拉普拉斯坐标进行了约束,\(\Delta\)代表拉普拉斯算子,拉普拉斯算子定义了网格中某个顶点与其相邻顶点之间的差异,可以度量网格中的局部形貌。添加这一项可以保留服装局部的褶皱细节。\(\omega\)是拉普拉斯均方误差项的系数,为固定值。
可以看出,训练服装形状特征\(S\)的时候施加了两个特别强的约束,就是为了能够以低维向量去表示输入的服装模型,可以有效降低运算量并提升网络的泛化能力。
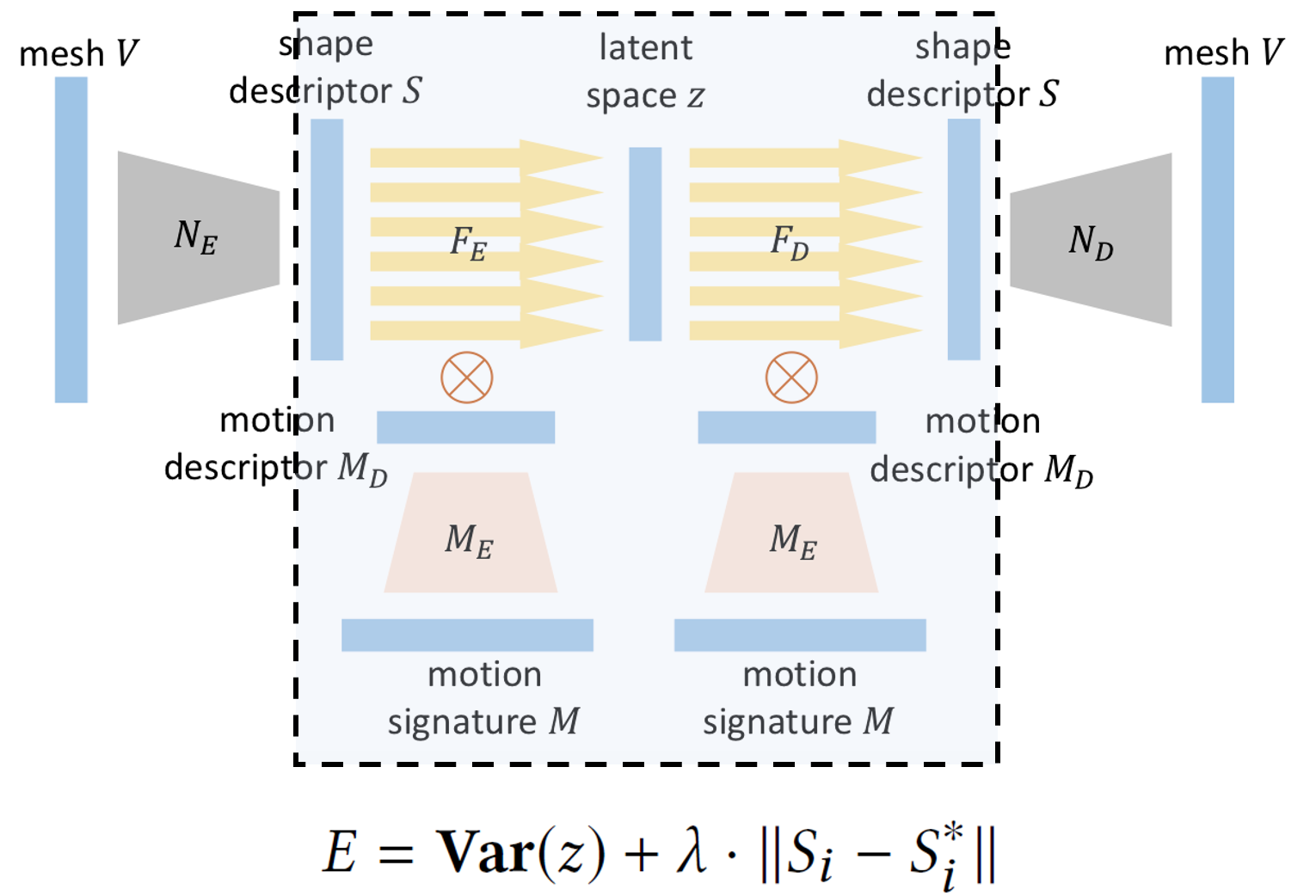
对于运动特征编码子网络,Loss由隐空间误差项、服装形状特征的平均绝对误差项两个部分组成:
-
服装形状特征的平均绝对误差项,\(S_{i}\)代表输入的服装形状特征,\(S_{i}^{*}\)代表重构后的服装形状特征,这样做是对重构前后的服装形状特征进行了约束,以确保隐空间不会变成0或者一个常数。
-
隐空间误差项。\(Var\)代表每个batch中\(z\)的变化,训练时每次都要处理若干件服装及其对应的姿态,\(Var\)记录了不同的\(S_{i}\)得到的\(Z_{i}\)间的变化。这样做的目的在于使同一批服装求解得到的隐空间的变化幅度最小,因为对于一批具有相同服装固有参数的服装应该被映射到隐空间\(z\)中相同的位置。
实验结果
该方法生成的服装模型存在部分的穿透,需要进行穿透修正。如下图,右侧为网络的原始输出,可以看出存在明显的穿透。往左依次为迭代1、2、3次后的服装模型,穿透现象逐渐减弱直至消失。
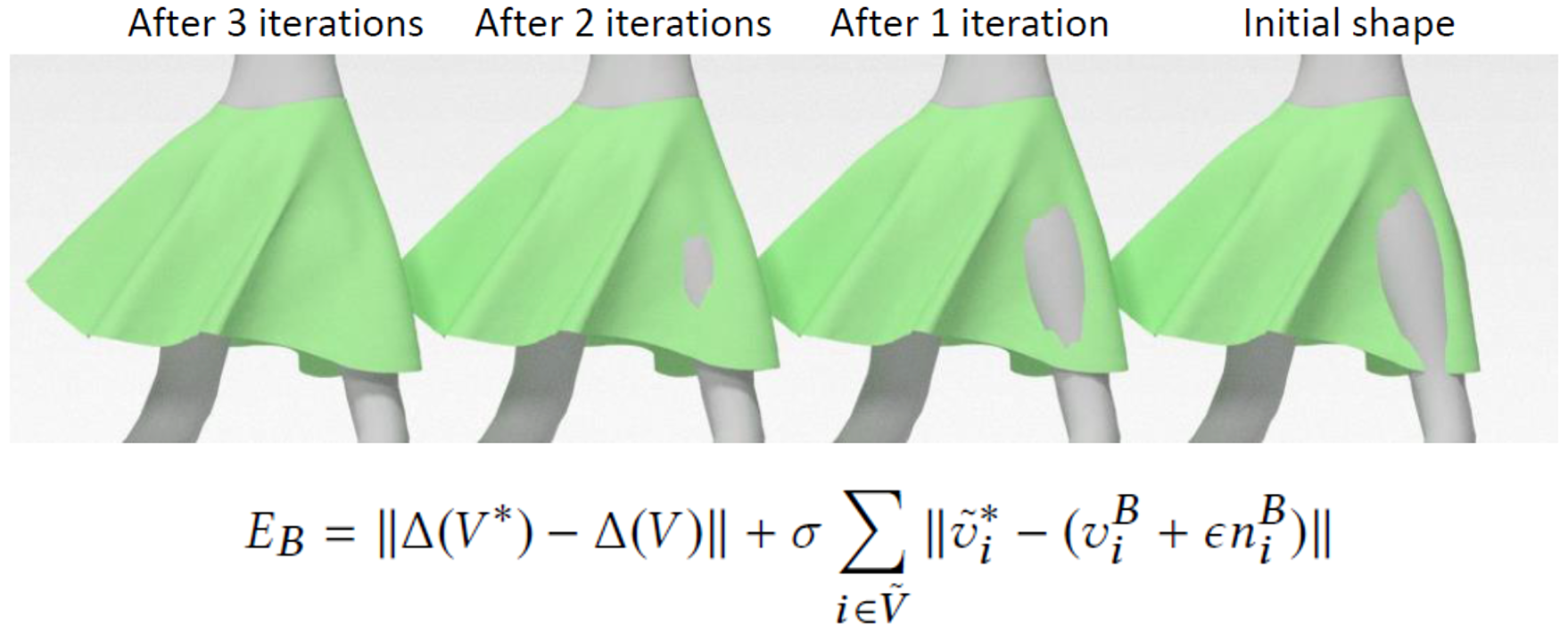
\(E_{b}\)是穿透修正的目标函数,由两部分组成:
-
(左)拉普拉斯平均绝对误差项,\(V\)是迭代前的服装,即网络输出的存在穿透的服装,\(V^{*}\)是迭代后的服装
-
(右)\(\tilde{v}_{i}^{*}\)代表存在穿透现象的服装顶点,\(v_{i}^{B}\)代表与\(\tilde{v}_{i}^{*}\)最近的人体顶点,\(\epsilon\)代表每次向外移动的步长,\(n_{i}^{B}\)代表人体模型顶点\(v_{i}^{B}\)的单位法线
也就是说,每经过一次穿透修正,服装模型中存在穿透的部分都以一定的步长被拉出人体。
接下来介绍实验结果。样本数据集的构成:
a)三款服装
b)相同姿态,不同服装的内在参数。训练时随机生成了200种不同参数的服装,并选取了3万帧人体运动进行训练,这样就形成了600万个帧序列用于训练。

作者首先验证了服装形状特征网络的提取能力:
-
Ground Truth
-
本文方法重构出的服装模型,完整的loss
-
不加拉普拉斯项
-
PCA,也就是主成分分析法。原理是将数据从高维的空间投影到低维空间上,使得投影后的数据方差最小,是一种线性的降维方法
蓝色的代表重构的服装与Ground Truth间的距离,颜色越亮代表误差越大

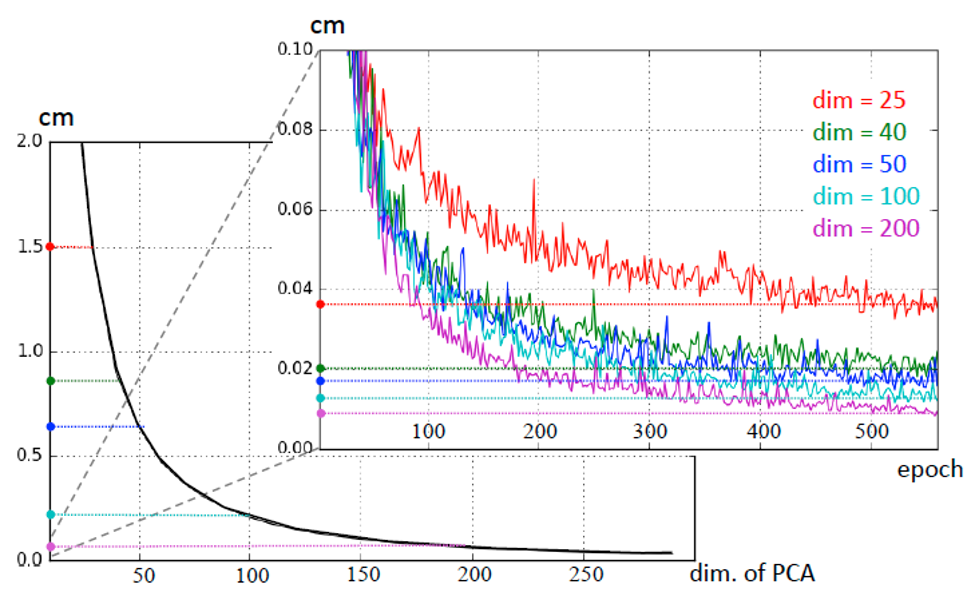
接下来是针对服装特征编码子网络的量化分析,左边那张是PCA的维度与重构误差间的关系图,可以看出,PCA的误差在厘米级。右边是文章中的服装形状特征提取网络的迭代次数与重构误差间的关系图,可以看出,误差在毫米级别。蓝色的是文章中服装形状特征所取的值,即50维。从25到50误差出现了明显的下降,而从50维到200维,性能提升相当有限。
下面的实验目的是为了证明网络可以学习到与人体运动无关的服装内在参数空间,一共有四组服装:
-
\(V\)为\(M\)姿态下的Ground Truth
-
\(V^{'}\)为网络生成的服装模型,并且可以得到对应的隐空间\(z^{'}\)
-
蓝色的代表\(V^{'}\)与\(V\)的距离
-
\(V_{1}^{'},V_{2}^{'},V_{3}^{'}\)为\(M_{1},M_{2},M_{3}\)姿态下利用\(z^{'}\)还原出的服装模型,这个隐空间是服装\(V\)的
可以看出,即使服装形状及人体姿态发生了变化,网络仍可以预测出给定姿态下的服装形变

然后是针对运动特征编码子网络的一些量化分析:
-
(左)不同方法的Loss与迭代次数之间的变化关系,红色的是作者提出的方法
-
(右)不同成分姿态特征下训练误差与迭代次数间的关系,姿态特征定义为当前帧与其前\(W\)帧的集合。\(W\)越大,误差越小。
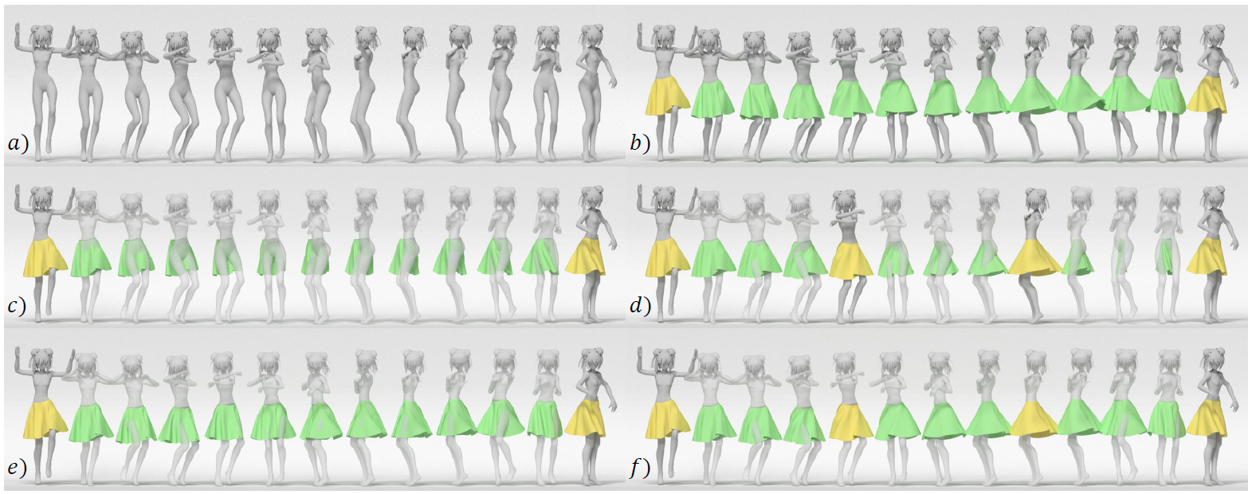
作者还给出了文章方法在动画创作领域的一个应用:
(a) 表示动作序列
(b) 表示将动作序列的第一帧和最后一帧设置为关键帧(黄)输入到网络,可以生成其它动作对应的服装模型(绿)
(c) 直接将两个关键帧进行线性差值的结果,存在严重的穿透、错位
(d) 表示添加更多的关键帧得到的结果,效果也不理想
(e) 仅使用服装形状特征提取的子网络生成的服装,也无法得到理想的结果
(f) 也是添加更多的帧,同样效果不好
总结
这篇文章的卖点在于:
-
提出了一种半自动化的服装动画设计方法,通过设定少量的关键帧以生成平滑、视觉上合理的服装动画;
-
提出了一种从服装模型中将不同服装固有参数相互分离的方法,也就是一开始的假设;
-
提出了一种服装动画合成方法,可以根据服装的固有参数和目标姿态对服装模型进行重构。
这篇文章的不足之处在于:
-
训练出的网络仅能够处理特定类型的服装和人体;
-
仅选取了当前帧对应的人体运动及该帧的前W帧进行训练,生成的服装动画仅蕴含了前W帧的运动信息。可能会丢失褶皱细节,并且服装模型可能与人体发生穿透;
-
需要花费大量时间去手动生成样本数据集:需要进行物理仿真。
项目是开源的,点击这里跳转。